Method
Click on each video to unmute or mute its generated audio.
Text input: Wheels spinning, and a slamming sound as the skateboard lands on concrete.
Text input: A beautiful orchestral piece that evokes a sense of wonder.
Text input: Whistling sounds, followed by a sharp explosion and loud crackling.
Text input: Water is rushing down a stream and pouring.
Text input: Waves on beach.
Text input: Ships riding waves.
Text input: Train (no text prompt given).
Text input: Playing tennis.
Text input: Playing bass drum.
Text input: Coyote howling.
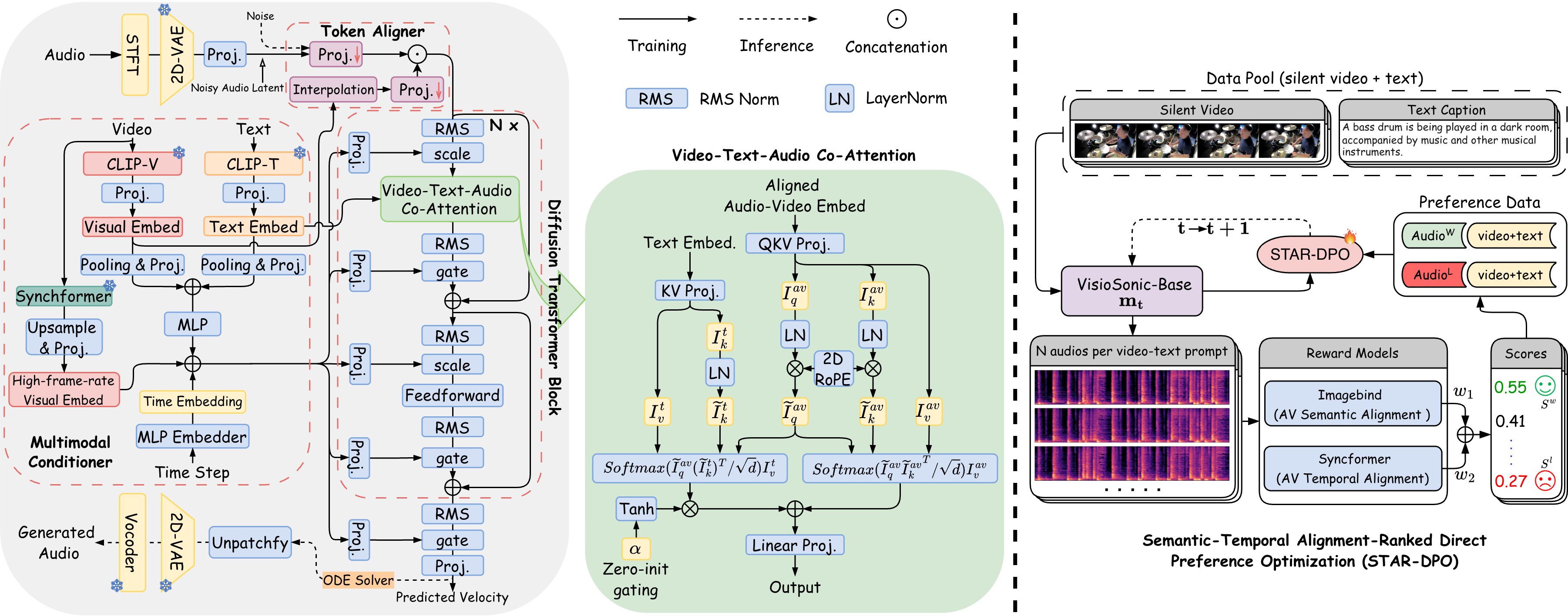
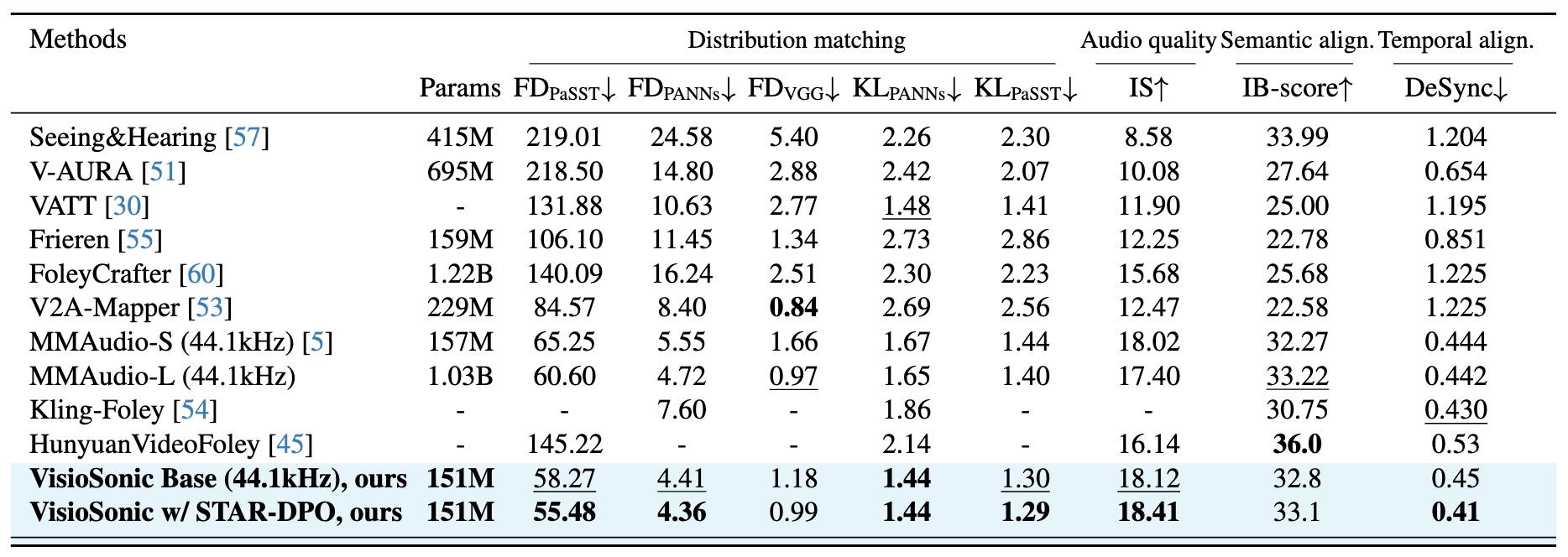
Generating high-fidelity audio that is both semantically meaningful and temporally synchronized with silent videos remains a challenging problem in video-to-audio generation. Existing approaches often fail to capture fine-grained temporal correspondence between visual events and audio dynamics, leading to unrealistic or desynchronized outputs. To address these limitations, we propose VisioSonic, a Video-Aligned Sound generation framework that unifies flow-matching diffusion and preference-guided alignment. VisioSonic introduces a multimodal conditioning module that jointly leverages video frames and textual cues to provide semantic and frame-level temporal guidance. A co-attention diffusion transformer efficiently fuses visual and audio representations, enabling content-aware sound synthesis with minimal computation costs. To further enhance alignment beyond supervised training, we introduce Semantic-Temporal Alignment Ranked Direct Preference Optimization (STAR-DPO), a novel preference-learning paradigm that automatically generates audio candidates, ranks them based on both semantic and temporal alignment, and subsequently fine-tunes the diffusion model using the derived preference pairs. Extensive experiments on various benchmarks demonstrate that VisioSonic achieves state-of-the-art audio-video synchronization and audio fidelity while using the fewest trainable parameters among competing approaches.
| Text Caption | Ground Truth | VisioSonic (ours) | MMAudio | SAH | FoleyCrafer | Frieren | VATT |
|---|---|---|---|---|---|---|---|
| train whistling | |||||||
| sloshing water | |||||||
| skateboarding |
| Text Caption | MovieGen Audio | VisioSonic (ours) |
|---|---|---|
| Wheels spinning, and a slamming sound as the skateboard lands on concrete. | ||
| Whistling sounds, followed by a sharp explosion and loud crackling. | ||
| Rhythmic splashing and lapping of water. | ||
| Ice cracking with sharp snapping sound, and metal tool scraping against the ice surface. | ||
| ATV engine roars and accelerates, with guitar music. | ||
| Shovel scrapes against dry earth. |
| Ships riding waves | Train (no text prompt given) | Seashore (no text prompt given) | Surfing |
|---|---|---|---|
| Typing | Water is rushing down a stream and pouring | Waves on beach | Water droplet |
|---|---|---|---|