
🎊 Welcome to my website!
My name is Kai (Alan) Wang. I’m a Ph.D candidate at The Edward S. Rogers Sr. Department of Electrical and Computer Engineering (ECE), University of Toronto, supervised by Prof. Dimitrios Hatzinakos. I also work closely with Prof. Yapeng Tian on Audio-Visual Learning and Generation.
My research interests lie in Multimodal Learning (Image/Video/Audio), Generative Models, and Multimodal LLM.

I’m always looking for research collaboration. If you are interested in my research, please don’t hesitate to reach out to me.
🔥 News
- 2025.08: 🎉 One paper is accepted by EMNLP 2025 (Findings).
- 2025.07: 🎉 One first-author paper is accepted by ACM MM 2025.
- 2025.07: 🎉 One first-author paper is accepted by BMVC 2025.
- 2025.01: 🎉 One paper is accepted by ICLR 2025.
- 2024.09: 🎉 One paper is accepted by NeurIPS 2024 (Spotlight).
- 2024.09: 🎉 One paper is accepted by EMNLP 2024 (Main).
- 2024.06: 🎉 One paper is appeared by ArXiv.
- 2024.05: 🎉 One co-first author paper is accepted by Pattern Recognition Letter.
- 2024.04: 🎉 One first-author paper is accepted by CVPR 2024.
- 2023.12: 🎉 One first-author paper is accepted by ICASSP 2024.
- 2023.07: 🎉 One first-author paper is accepted by APSIPA 2023.
- 2022.09: 📖 Starting my Ph.D study at the University of Toronto.
📝 Selected Publications
( * equal contribution)

Self-Improvement in Multimodal Large Language Models: A Survey
Shijian Deng, Kai Wang, Tianyu Yang, Harsh Singh, Yapeng Tian.
EMNLP 2025 (Findings)
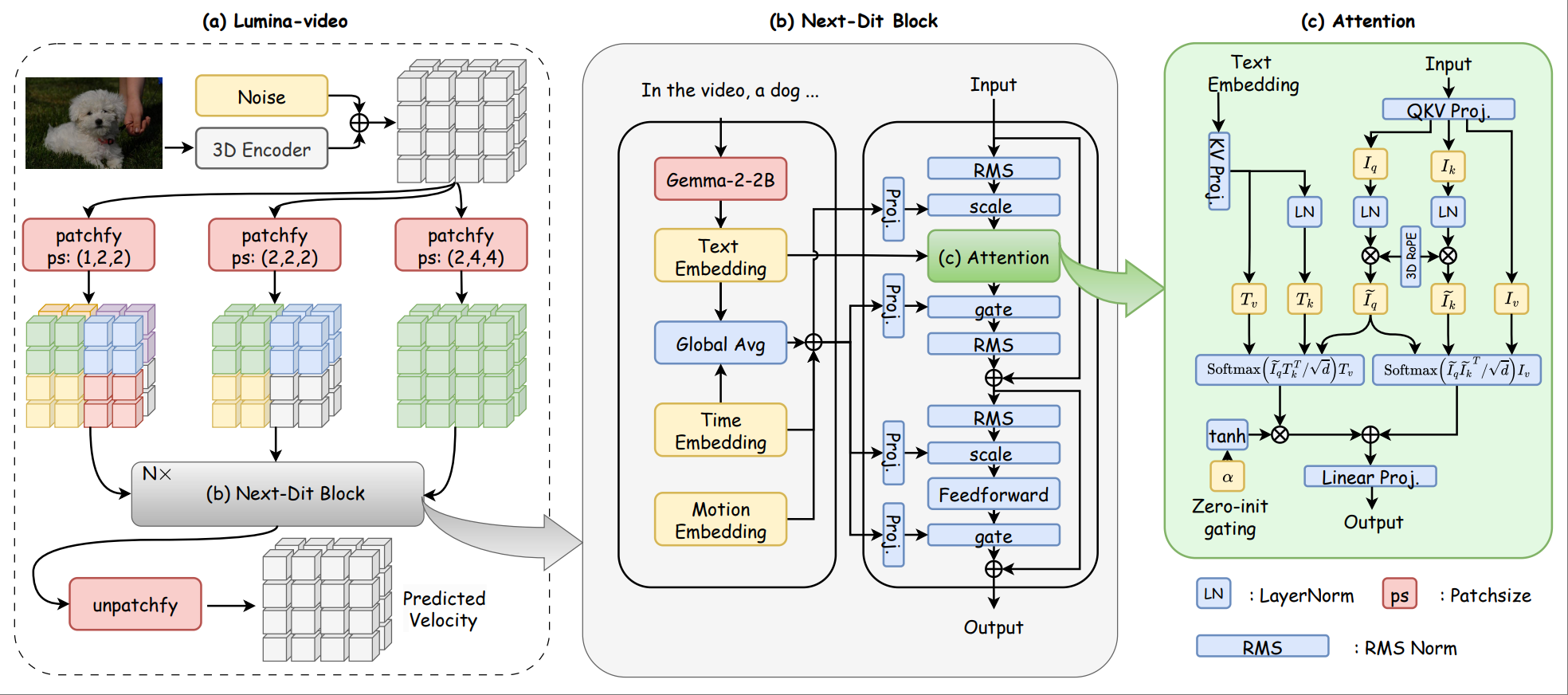
Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT
Dongyang Liu*, Shicheng Li*, Yutong Liu*, Zhen Li*, Kai Wang*, Xinyue Li*, Qi Qin, Yufei Liu, Yi Xin, Zhongyu Li, Bin Fu, Chenyang Si, Yuewen Cao, Conghui He, Ziwei Liu, Yu Qiao, Qibin Hou, Hongsheng Li, Peng Gao
Under Review
Prompt Image to Watch and Hear: Multimodal Prompting for Parameter-Efficient Audio-Visual Learning
Kai Wang, Shentong Mo, Yapeng Tian, Dimitrios Hatzinakos.
BMVC 2025 (Poster)
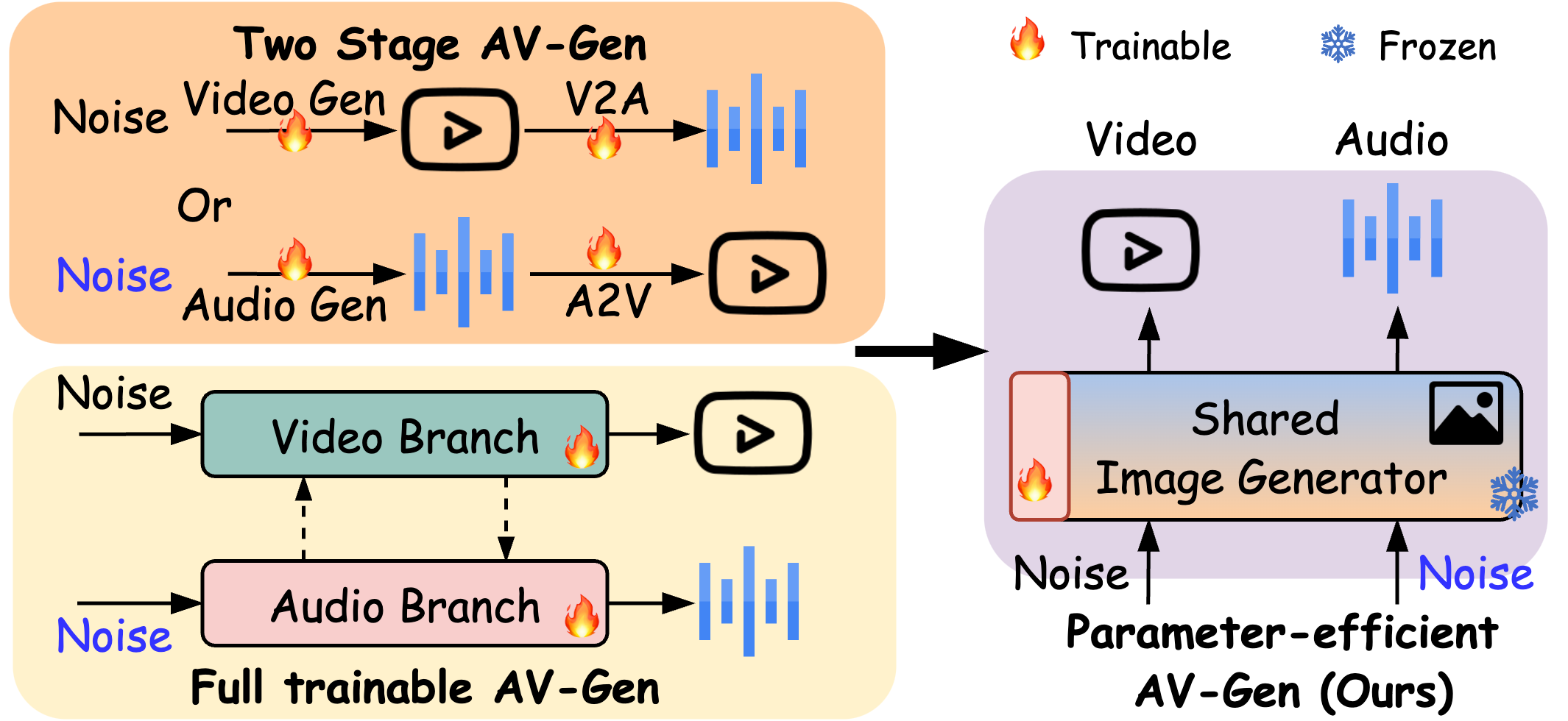
AV-DiT: Taming Image Diffusion Transformers for Efficient Joint Audio and Video Generation
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, Yapeng Tian.
ACM Multimedia 2025 (Oral)
- We design an efficient audio-visual diffusion transformer generate high-quality, realistic videos with both visual and audio tracks.

MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, Wenhu Chen.
NeurIPS 2024 (Spotlight)
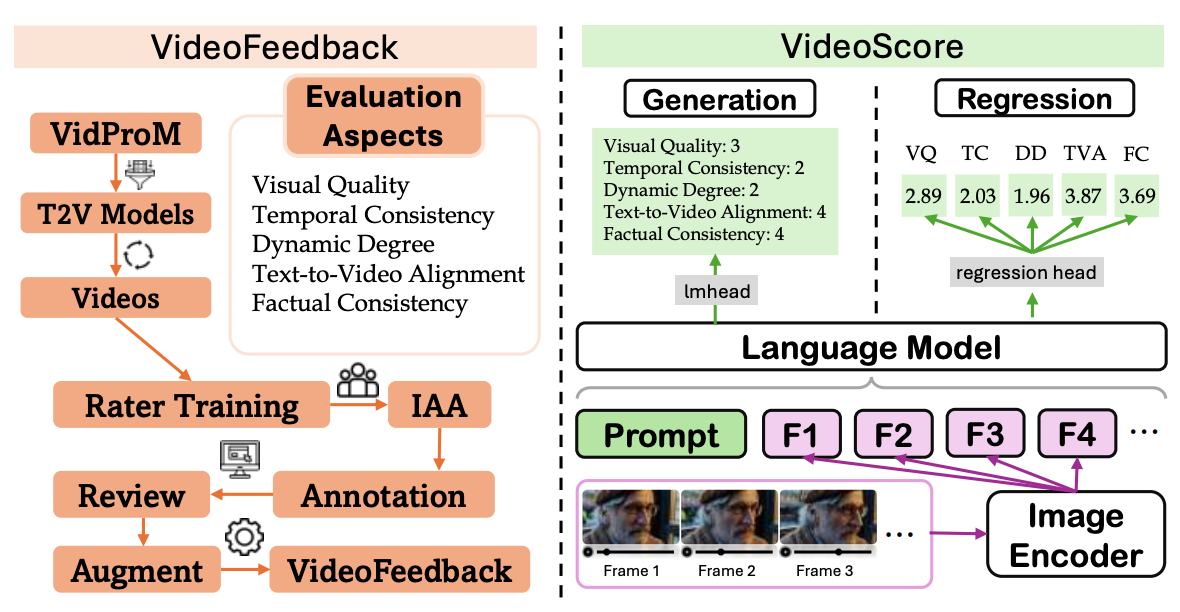
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, Kai Wang, Quy Duc Do, Yuansheng Ni, Bohan Lyu, Yaswanth Narsupalli, Rongqi Fan, Zhiheng Lyu, Yuchen Lin, Wenhu Chen
EMNLP 2024 (Main)
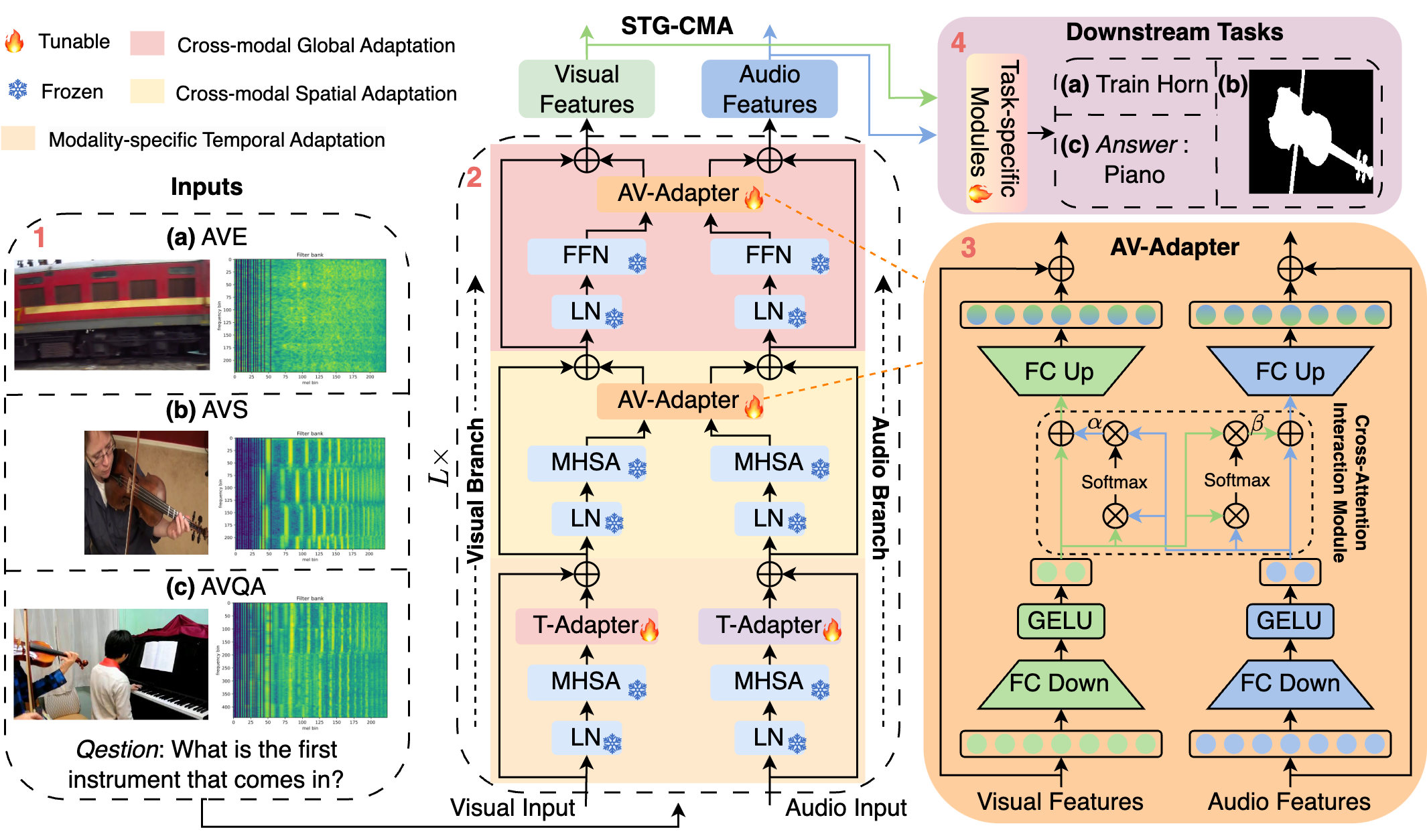
Kai Wang,Yapeng Tian, Dimitrios Hatzinakos.
CVPR 2024 Workshop
- We propose a Spatial-Temporal-Global Cross-Modal Adaptation (STG-CMA) to gradually equip the frozen ViTs with the capability for learning audio-visual representation.
Alireza Esmaeilzehi*, Ensieh Khazaei*, Kai Wang*, Navjot Kaur Kalsi, Pai Chet Ng, Huan Liu, Yuanhao Yu, Dimitrios Hatzinakos, Konstantinos Plataniotis.
Pattern Recognition Letter
- We propose a novel dataset for the task of human activity recognition, in which the labels are specified for the working environments.
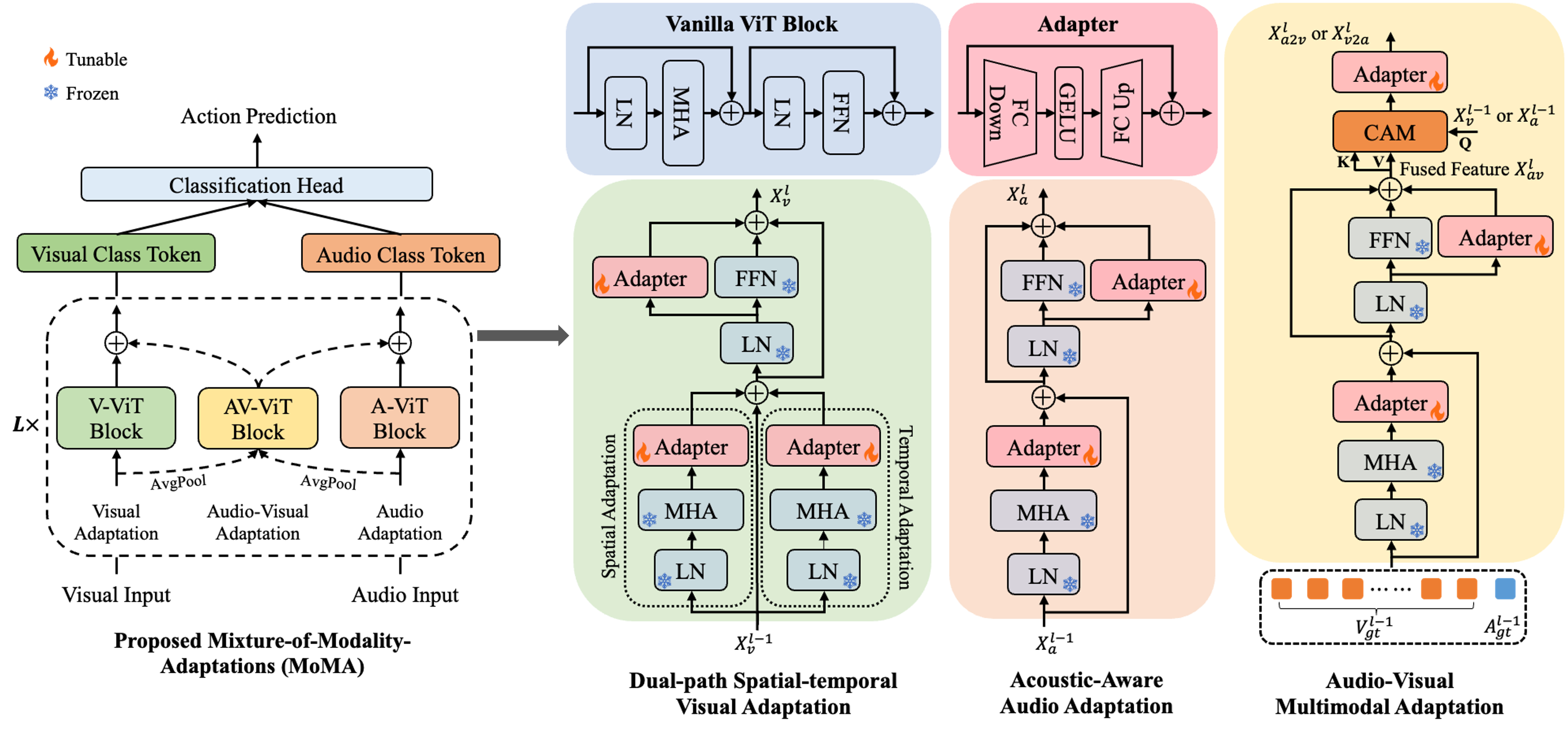
Kai Wang, Dimitrios Hatzinakos.
ICASSP 2024 (Oral)
- We propose a novel parameter-efficient scheme called Mixture-of-Modality-Adaptations (MoMA) for audio-visual action recognition.
- We propose the SEformer, an efficient dual-path conformer neural network for speech enhancement.
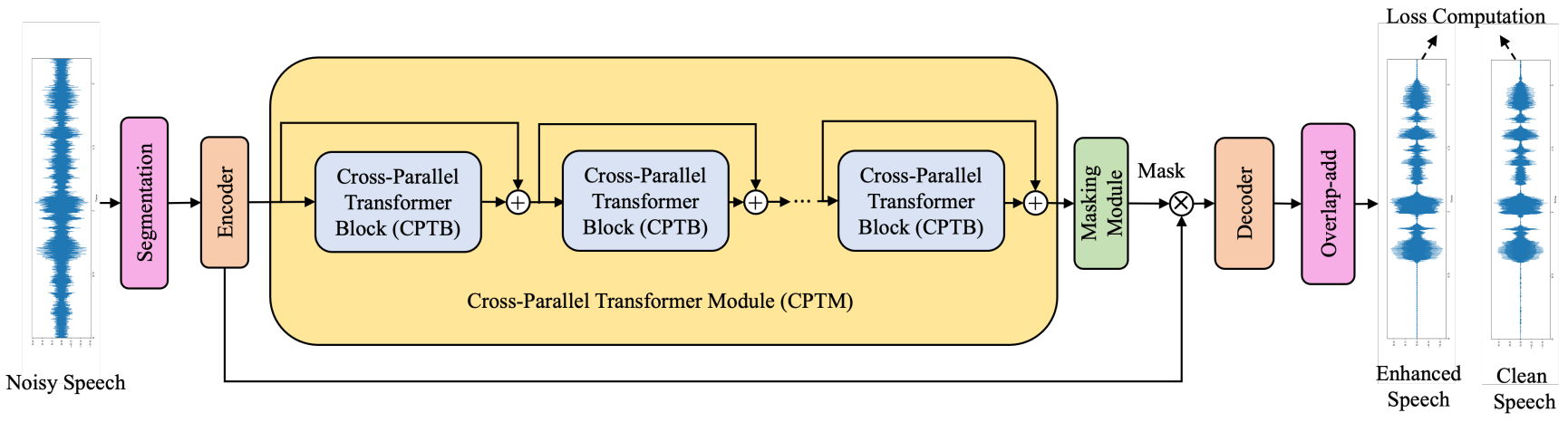
Cptnn: Cross-parallel transformer neural network for time-domain speech enhancement
Kai Wang, Bengbeng He and Wei-Ping Zhu.
IWAENC 2022
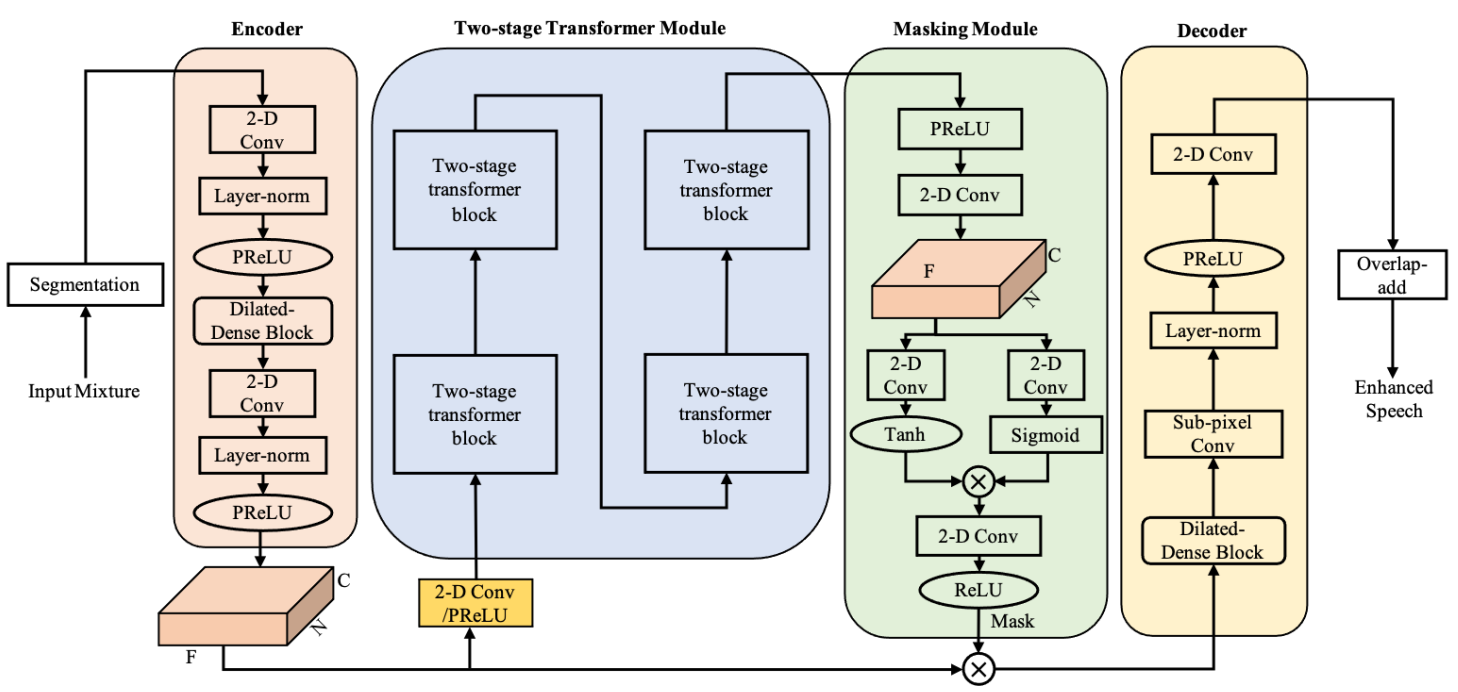
TSTNN: Two-stage transformer based neural network for speech enhancement in the time domain
Kai Wang, Bengbeng He and Wei-Ping Zhu.
ICASSP 2021
🎖 Honors and Awards
- 2024: School of Graduate Studies (SGS) Conference Grant, University of Toronto
- 2022 - Present: Edward S. Rogers Sr. Graduate Scholarships, University of Toronto
- 2022 - Present: Research Fellowship, University of Toronto
- 2021: Conference and Exposition Award
- 2015: Meritorious Award of International Mathematical Contest in Modeling
🏁 Services
- Conference Reviewer: ICLR, ACM MM, BMVC, CVPRW, ICASSP, ICME, ICJNN
- Journal Reviewer: IJCV, Systems, and Signal Processing (CSSP), Speech Communication
🧑🏫 Teaching
- Winter (2023, 2024), Fall(2023, 2024): ECE421 Introduction to Machine Learning
- Winter 2025: ECE462 Multimedia
- Fall 2025: ECE 1786 Creative Applications of Natural Language Processing
© Kai Wang | Last updated: Aug. 17, 2025 | Theme by Yi Ren